




Tests are great because they give us the confidence we need to refactor code and change the structure of our systems over time without breaking existing functionality.
I think tests are even more important when you have to work on legacy systems. They provide you with live and executable documentation on how the system works and what functionality is currently available.
When I join a new team, the first thing I do on the project is to run all the tests. This gives me confidence as a new developer on the team that whatever changes I’m going to make will not break existing behaviour in production.
Over time, these test suites grow, and after several developers have worked on a service, things tend to get out of hand. Your test suite tends to get very complex and hard to understand by new developers. It also takes an increasing amount of time to run your entire suite. In our case, we had a bit of both. Our entire test suite took roughly 30 minutes to run on our continuous integration pipeline. When you add to that intermittent failing specs, that time grows exponentially high, depending on how many times you need to re-run them.
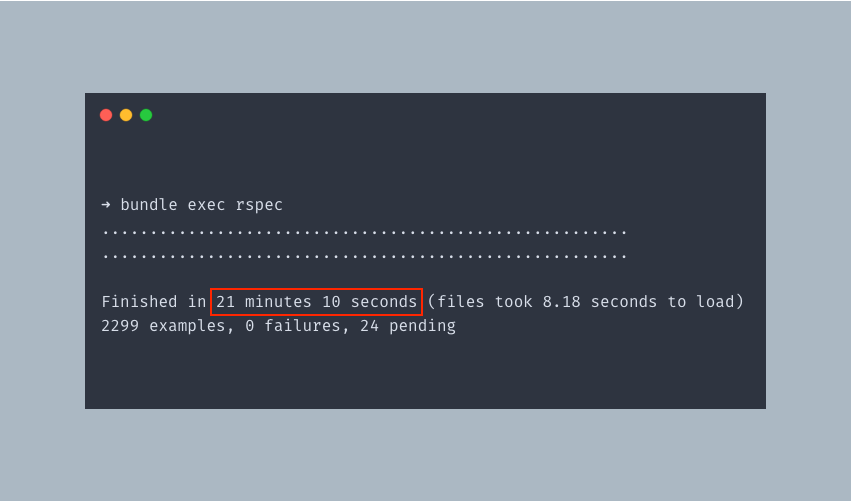
The time it took to run the entire test suite before the improvements we made.
In this post, I'll share a few strategies we used to reduce that time drastically. Our build time, at the time of this writing, is now down to 5 minutes.
RSpec configurations
Before rspec-rails 3.x, a single spec_helper.rb file was generated. This file contains all RSpec configurations for your project. When configuring rspec-rails for Rails applications now you get a spec_helper.rb and a rails_helper.rb. This was done to keep the installation process in sync with regular RSpec changes, but also, to provide a way to avoid loading Rails for specs that do not require it. You can read more about this here.
spec_helper.rb
This file should only contain the bare minimum configuration to run your tests with RSpec. Keep this file as slim as possible and only add the configuration required by all types of tests.
rails_helper.rb
Here you can add your Rails-specific configurations. This should be required for specs that require Rails to be loaded (controller, feature, system and model specs).
It takes on average 8s to load Rails before your tests example are executed. If you practice TDD, you want to have quick feedback from your specs. Having to wait for 8s every time you run your tests adds up, especially if you're writing a spec for a pure Ruby object that doesn't depend on Rails.
Interaction with the database
The next thing we looked at was how we interacted with the database in our tests. Improvements in this area gave us the biggest speed boost. There are 2 areas we had to focus on; database cleaning strategies and the creation of test data
DB cleaning strategies
There are 3 strategies for cleaning your database during your test execution:
Transaction
Truncation
Deletion
For us to optimize for time, it was important to understand how each of the above strategies works, to choose the right one for our scenario.
One thing that makes Rails appealing to developers is the fact that you can get started easily and get going without having to worry about the underlying
DB cleaning using transaction
“A transaction, in the context of a database, is a logical unit that is independently executed for data retrieval or updates. In relational databases, database transactions must be atomic, consistent, isolated and durable -- summarized as the ACID acronym.”
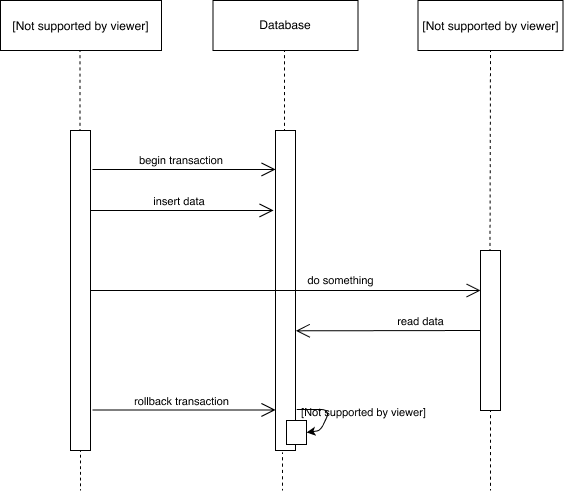
Cleaning with transaction
Looking at the above diagram, assume we have a spec for a given system and we've configured RSpec to clean the database using transaction. When we start the execution of the spec, a transaction begins. We then create some data in the setup phase of the spec; exercise the system under tests and validate our expectations. Once this process is done, all changes to the database get rolled back and the transaction ends.
Because everything is wrapped in a transaction, all database queries are kept in memory and not committed, which means nothing gets physically written to disk. Because of this, the execution of the specs is quite fast.
A couple of things to watch out for when using this strategy:
Everything you create, before you execute your specs will remain in the database after each spec is executed.
Table IDs do not reset their count to 1 in between specs, so be wary of specs that expect an object to have a specific ID
This strategy can cause issues with specs that rely on multiple database connections or have multiple threads trying to access data created within a transaction.
Because of this last point, a lot of our feature specs were set up to use truncation as a cleaning strategy.
DB cleaning using truncation
With truncation, data is written to disk and after we execute every spec, the database is truncated. This ensures that we always have a clean slate in between specs. Also, because data is written to disk, feature specs with multiple threads have no problem accessing data that was created in the setup phase from the browser that's running in a separate thread.
Most apps I had worked with so far made use of the Database cleaner gem which provides an easy DSL to switch between both cleaning strategies.
On the flip side, because of the constant write to disk, things get really slow when using this strategy to clean the database when running specs.
We moved a portion of our specs to use transaction as a cleaning strategy, and the other half remained on truncation. The goal was to slowly migrate all of them to use transaction and speed up our test run time.
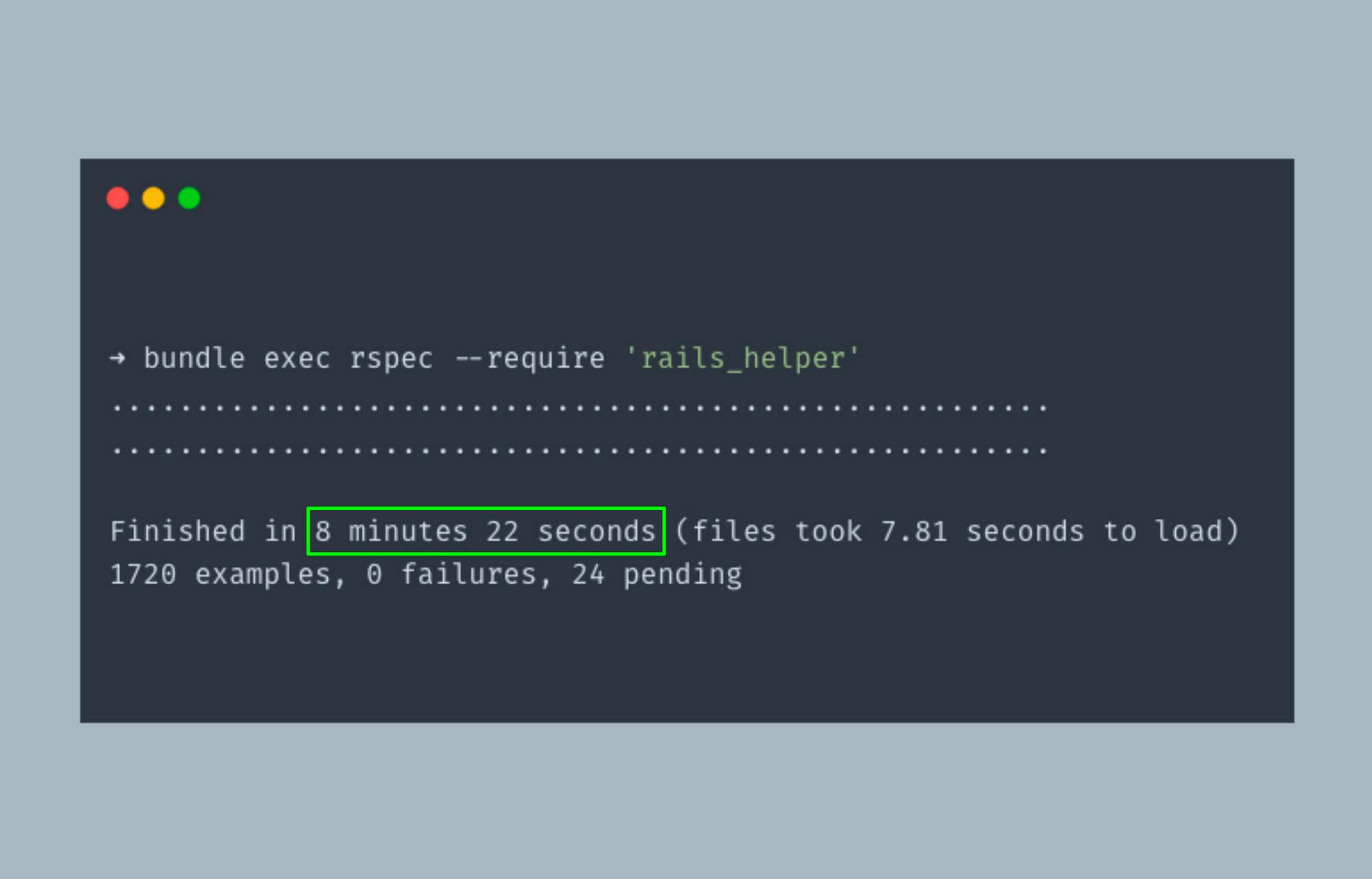
The first group of specs running with transaction strategy
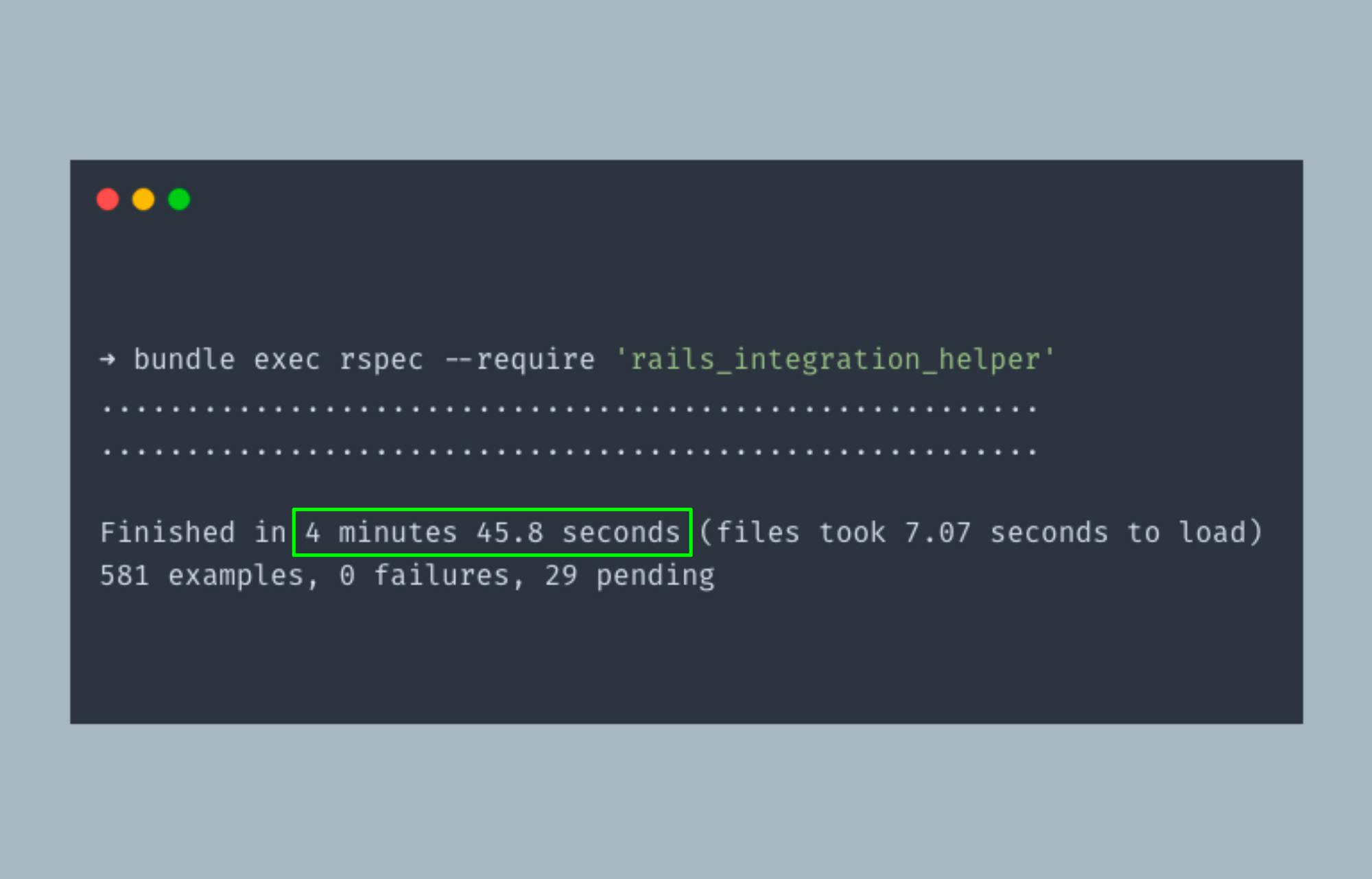
The second group of specs runs with truncation strategy
We were able to achieve this by having separate RSpec configurations with different strategies and loading each one with the relevant group of specs. Rails support transactions out of the box with a feature name Transactional Fixtures. It behaves just like the transaction strategy of DatabaseCleaner. Additionally, as of Rails 5.1+, there is now better support for multiple database connections. So, if you're using capybara for your feature specs you should be able to get them to run using transaction instead of truncation.
Running both groups in parallel in our continuous integration pipeline meant our tests now took about 8 mins vs 21 mins. Progress!! But we didn't stop there. We identified a few other points that were cause for troubles in our system and had to address them. I'll briefly go over some of those in the next section.
Miscellaneous
Don't create data using database migrations
Database migrations are executed before test runs. With us moving to transaction as a cleaning strategy, if you remember I mentioned earlier that anything that is created before your specs will remain in your database and will not be cleaned. This was the cause of a lot of intermittent failures for us because some tests would assume that the database was in a given state when in reality it wasn't.
Also, new developers joining your team will likely not know that migration in your application is creating a set of data and will spend hours trying to debug their specs to figure out why they have multiple records in the database instead of just the one they just created.
We stopped doing that and moved all initial data creation to seed scripts.
Only create the data you need
Interacting directly with the database is fairly expensive and can slow down specs quite a bit. As such, you want to ensure that you create just enough data for your specs.
We had a few integration specs that only needed one or two records, but looking at the setup were creating thousands of entries in our database before running the specs.
Factories: You're probably using them wrong
We use FactoryBot to create factories for our specs. FactoryBot gives us several methods to create factories.
FactoryBot.create(:model_name) - This method will return a model instance and saves it to the database. This is fine if you're writing a spec that really requires that data be written to your database.
Most of the time it's enough to have just an in-memory representation of that object/model. This is why we're not defaulting to using FactoryBot.build(:model_name) and only use .create when necessary. When you need to write specs that check specific ActiveRecord interactions or relations, you can make use of FactoryBot.build_stubbed(:model_name). This works like .build but will also assign a fake ActiveRecord ID to the model and stub out db-interaction methods like save.
Wrap up
Below are some key take away from this exercise:
Prefer transaction over truncation;
Avoid excessive interactions (read/write) to your test database;
Only create the data you need for your tests;
Don't use database migrations to seed your database, or be ready to deal with weird flaky specs.
You might not need the Database Cleaner gem at all and you should be able to use transactional fixtures for most, if not all your types of tests.
At the time of this writing, we've moved a good chunk of our specs over to use the transaction strategy and with some of the things we've been paying attention to when writing specs, we're down to about 5 mins.

First group of specs running with transaction strategy
And the second group of specs now takes about 2 mins.
Second group of specs running with trunction strategy